

AI自動化の「ハンドブレーキ」はあなた自身だ——カオス・トークン限界・古いデータ、失敗するAI導入の3つの正体
「ゴミを自動化すると、高速なゴミが生まれる」——Bloofusion CROアナリストが語った、規律なき自動化の代償
- 「カオスを自動化すると高速なカオスが生まれる」——AI導入が失敗する根本原因
- トークン(Token)の限界とデータベースクラッシュ——LLMの物理的制約を正しく理解する
- RAG(検索拡張生成)とベクターデータベースの仕組み——ノーコードで実装する方法
- ハッピーパスしか考えない素人とプロの差——エラーハンドリング設計の実務
- タイミング制御と非同期処理——AIが深夜3時に送信してはいけない理由
- 「古いデータが新しいデータに勝つ」情報鮮度の問題とSSSOTの確立
- 日本企業が今すぐ始めるべき3つのアクション
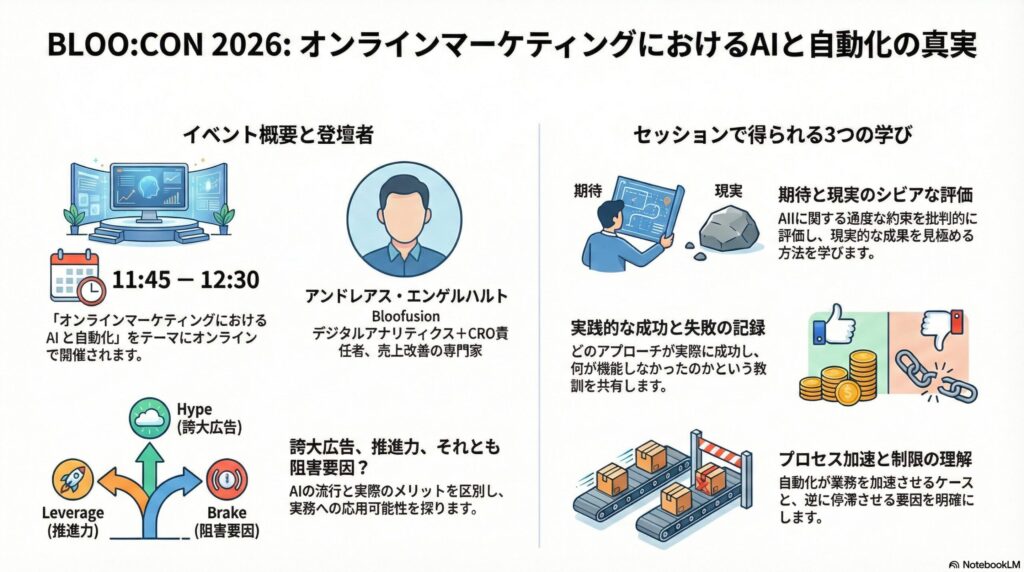
2026年1月29日、ドイツ・ケルン。BLOO:CON 2026のランチ前最後のセッション(11:45〜12:30)は、午前中の「トレンドと戦略」の空気を一気に「現実」へと引き戻した。登壇者は、BloofusionのデジタルアナリティクスおよびCRO(コンバージョン率最適化)責任者、Andreas Engelhardt(アンドレアス・エンゲルハルト)氏。テーマは「オンラインマーケティングにおけるAIと自動化——誇大広告(Hype)、レバー(Lever)、それともハンドブレーキ(Handbrake)?」だ。
ハイプ(Hype)
「AIがすべてを自動化する」「マーケターは不要になる」——現実を無視した誇大広告。期待と実態のギャップが組織を混乱させる。
レバー(Lever)
データ整備・プロセス標準化・エラー設計が揃った組織において、AIは競合を置き去りにする最強の加速装置になる。
ハンドブレーキ(Handbrake)
間違った自動化は業務を複雑にし、ブランドを破壊し、組織の成長に急ブレーキをかける。ハンドブレーキの正体は「私たち自身」だ。
Bloofusion Germany GmbH デジタルアナリティクス+CRO責任者
コンバージョン率最適化とデジタルアナリティクスの専門家。数々のクライアントワークでAI導入の失敗と成功を経験し、「自動化の前に標準化」という実務哲学を体系化した。
第1章:AIがハンドブレーキになる理由——「カオスの自動化」という最大の失敗
「ゴミのプロセスをAIで自動化すると、出力は高速なゴミだ」
多くの企業が陥る失敗の根本原因は一語で表せる——「カオス(Chaos)」
データが整理されていない状態・業務プロセスが未定義な状態でAIを導入しても
「高速で生成されたカオス」しか生まれない。
エンゲルハルト氏は、CRMの顧客データに名前の表記揺れ・重複・メールアドレス欠損が放置されている状態で「AIでパーソナライズメールを自動送信するフロー」を組んだ場合の惨状を語った。「様」が抜けたメール、重複送信、解約済み顧客への勧誘——人間なら気付けるミスを、AIは秒速で数万件実行する。

自動化の前に、標準化。この順序を間違えたプロジェクトは100%失敗します。AIを入れる前に、まず人間が「データの掃除(クレンジング)」と「業務の標準化」を行わなければなりません。
この教訓を「Before / After」で視覚化すると次のようになる。
この教訓はLIFRELLのクライアント支援でも繰り返し経験する。「AI導入の前に業務の棚卸しをする」という作業を省略するプロジェクトは、必ずどこかで破綻する。「AIを入れれば何とかなる」という期待は、実際には「現在の問題を加速・拡大する装置を入れる」ことに等しい。エンゲルハルト氏の「標準化→自動化」の原則は、日本の企業文化において特に重要だ。承認プロセスが複雑で例外処理が多い日本の業務フローは、そのままAI化すると例外の嵐を自動生成する。
第2章:LLMの物理的限界——トークンとデータベースクラッシュを正しく理解する
「AIを無限の知識を持つ魔法使いだと思っていませんか?」
エンゲルハルト氏が次に指摘したのが、多くのマーケターが見落としているLLM(大規模言語モデル)の物理的制約だ。
| 誤解 | 現実 | 結果 |
|---|---|---|
| 「全商品データをAIに読み込ませれば何でも答えてくれる」 | コンテキストウィンドウに上限がある。数万件の商品データを一度には処理できない | AIはエラーを吐くか(クラッシュ)、最初の情報を忘れて(忘却)、もっともらしい嘘をつく(ハルシネーション) |
| 「過去10年分の顧客対応履歴をすべて学習させる」 | 毎回すべてのデータを読み込ませるのはコスト・精度の面で現実的でない | コストが爆発するか、精度が著しく低下する |
| 「データベースをそのまま全部AIに連携する」 | 「今必要な情報だけ」を切り出して渡す技術が必要 | システムが破綻する |
データバンク(Database)は大きすぎて、そのままモデルに渡すことはできません。AIが扱えるのはトークン(Token)という単位に区切られた「窓」の中だけです。窓の外は見えない——それがLLMの現実です。
第3章:RAGとベクターデータベース——「本全体」ではなく「該当ページ」だけをAIに渡す
トークン限界の解決策として、エンゲルハルト氏が解説したのがRAG(Retrieval-Augmented Generation:検索拡張生成)だ。
チャンキング
AIが読みやすいサイズ(段落・セクション単位)に切り分けることで、後の検索精度を高める。「辞書を丸ごと渡す」のではなく「辞書を単語カードに分解する」イメージ。
埋め込み
各チャンクを数値空間に変換することで、AIは「言葉の意味的な近さ」を計算できるようになる。これがベクターデータベース(Pinecone等)に格納される。
検索
全データを読むのではなく、質問と関連性の高いチャンクだけを選択的に取得する。データ量がどれだけ多くても、渡すのは「関連する一部」だけ。
生成
絞り込まれた少量の関連情報だけを渡すことで、精度が上がりコストが下がる。ハルシネーションも大幅に低減できる。
Pythonコードを書かなくても、Make.comを使えばRAGシステムを構築できる。「Google DriveのPDFを読み込む」→「OpenAIでベクトル化する」→「Pinecone(ベクターDB)に保存する」という一連の流れをドラッグ&ドロップで自動化できる。これからのマーケターに必要なのは、この「データのパイプラインを設計する力」だ。
RAGは2024〜2025年にかけて急速に実用化が進んだ技術だが、「どのようなチャンクサイズで分割するか」「どのような埋め込みモデルを使うか」という設計の質が、回答精度を大きく左右する。LIFRELLが支援するプロジェクトでも、RAGの設計の善し悪しが「使えるAIシステム」と「使えないAIシステム」を分ける最大の差別化要因になっている。Make.comを使ったノーコード実装は入門として優れているが、本番運用ではチャンク戦略の最適化が不可欠だ。
第4章:プロとアマの差——「ハッピーパス」しか考えないフロー設計の罠
エラーハンドリング——現実はハッピーパスの外にある
技術的な基盤が整ったとして、次はフロー設計の品質だ。エンゲルハルト氏が言う「初心者が必ず犯す失敗」が「ハッピーパス(すべてが上手くいく前提の設計)」だ。
OpenAIのサーバーがダウンしていたら? タイムアウトが発生したら? 対応なしでは処理が止まり、担当者が気づかないまま何時間も放置される。
✓ 対策:5分後に自動再試行 → それでも失敗なら担当者にSlack通知を送る
商品価格が空欄だったら? 顧客名が未入力だったら? AIは欠損を無視して処理を続け、「価格:なし円」のメールを送信する。
✓ 対策:必須フィールドの存在チェックをフロー冒頭に置き、欠損があれば処理を中断してアラートを出す
AIが競合他社の製品名を含む文章を生成したら? 差別的な表現が混入したら? 自動公開フローでは人間が気づく前に配信されてしまう。
✓ 対策:禁止ワードリストによる出力チェック → 引っかかったらレビューキューへ送信
プロフェッショナルな自動化フローには、必ず「エラーハンドリング(Error Handling)」が含まれています。こうした「防波堤」を何重にも張り巡らせることこそが、本当の自動化設計です。
タイミング制御と非同期処理——AIのリズムを人間のリズムに合わせる
人間リズムへの同期
AIが深夜3時に素晴らしいメールを書いても、その瞬間に送信してはいけない。顧客が開封しやすい翌朝9時まで「待機(Sleep)」させるフローが必要だ。AIは24時間動けるが、受け取る側の人間はそうではない。
非同期(Asynchronous)な承認連携
AIが生成したコンテンツを、人間が即座にチェックできるとは限らない。スプレッドシートやCMSの下書きに保存し、人間がチェック完了のステータスに変更した瞬間に公開トリガーが引かれる設計が、現場のストレスを減らす。
第5章:「古いデータが新しいデータに勝つ」——ナレッジマネジメントという最大の落とし穴
エンゲルハルト氏がセッション後半で最も熱弁したのが「ナレッジマネジメント(知識管理)」の難しさだ。
ある企業がAIチャットボットに「過去の全マニュアル(2020年版〜2026年版)」を無差別にインポートしてしまいました。AIは顧客に対して、今はもう廃止された古い機能を自信満々に案内し始めました。AIにとって2020年のドキュメントも2026年のドキュメントも、単なる「テキストデータの塊」に過ぎません。「こっちの日付が新しいから古い方は無視しよう」という判断は、メタデータとして明示的に指示しない限りできないのです。
- バージョン管理の自動化:古いデータには「Deprecated(非推奨)」タグを自動付与するか、ベクターデータベースから物理的に削除するフローを組む
- SSOT(Single Source of Truth)の確立:「価格情報は必ずPIM(商品情報管理)を参照する」「仕様は必ず最新のPDFを参照する」という参照元の優先順位をAIに厳守させる
- 更新トリガーの設定:ソースドキュメントが更新されたとき、自動的にベクターDBも再インデックスするフローを組む
- 定期的なデータ監査:月次または四半期ごとに、AIが参照しているデータの「鮮度チェック」を人間が行う運用体制を作る
「インポートして終わり」ではなく「インポートしてからが始まり」——これはLIFRELLが支援するRAG導入プロジェクトで必ず説明する原則だ。特に日本企業は「プロジェクトとして完了させる」という文化が強く、メンテナンス体制を最初から設計しないケースが多い。AIは「腐ったデータを食べると腐った出力をする」——この単純な事実を、経営層が理解した上でAI導入の意思決定をするかどうかが、プロジェクトの成否を分ける。
第6章:「プロトタイプ」から始める——APIエコノミーと小さく速いアジャイル開発
エンゲルハルト氏は最後に、企業の開発体制そのものの変革を訴えた。
| 比較軸 | 失敗するアプローチ | 成功するアプローチ |
|---|---|---|
| スコープ | 全社規模の巨大自動化システムを一気に構築 | 小さな1つのフローから始め、動いたら拡張する |
| データ連携 | ツール内だけの閉じた自動化 | APIを通じてGA→Salesforce→Google Adsのようにツールを横断するデータフロー |
| 完成度 | 「完璧」を目指して公開を遅らせる | 70%の完成度でプロトタイプを動かし、エラーから学ぶ |
| エラー対応 | ハッピーパスのみ設計 | エラーハンドリングを最初から多重設計 |
| データ管理 | インポートして終わり | バージョン管理・SSOT・定期監査まで設計に含める |
まずは小さなフローから始めること。プロトタイプを作り、エラーが出たら修正する。この「アジャイルな開発サイクル」を高速で回せるマーケティングチームだけが、AIの恩恵を享受できます。
日本企業が今すぐ始めるべき3つのアクション
AI導入プロジェクトの前に、まずアナログで業務フローをホワイトボードに書き出し、無駄を削ぎ落とし、標準化する。CRMのデータクレンジング(重複排除・欠損補完・表記統一)を完了してからでなければ、AI導入の効果は出ない。「掃除が終わってから自動化する」の原則を、経営レベルで方針として定めること。
SQLを書けなくてもいい。しかし「RAGとは何か」「なぜトークン制限があるのか」「ベクターデータベースがなぜ必要か」を理解していなければ、AIベンダーと対等に話すことも、正しい要件定義をすることもできない。社内勉強会でこの3つの概念を共有し、「AI技術の基礎理解」を組織全体に浸透させることが急務だ。
コピーライティングスキル以上に、「MakeやZapierを使ってAのツールとBのツールをつなぎ、エラー処理を組み込む力」が必須になる。この「オートメーション・アーキテクト」という役割を社内で定義し、育成または採用することが、AI時代の組織競争力の鍵だ。外注で賄える部分もあるが、自社業務を熟知した内製人材が担う方が品質は高い。
LIF Tech編集部 総括——「ハンドブレーキをかけているのは私たち自身だ」
エンゲルハルト氏のメッセージは、AIに対する過度な期待(Hype)を戒め、実務的な規律(Discipline)を強く求めるものだった。
「AIと自動化は、私たちの仕事を楽にしてくれるわけではありません。むしろ、『データを整理する』『プロセスを定義する』『知識を更新し続ける』という、人間がこれまでサボってきた仕事を、より厳格に求めてきます。」
しかし、その泥臭い準備と規律を守り抜いた企業にとって、AIは競合を置き去りにする最強のレバーになる。ハンドブレーキをかけているのはAIではない。整理されていないデータと、古いマインドセットを持つ私たち自身だ。
