

AI検索対策(GEO)の本質は、AIが回答を生成する際の根拠とする「コンセンサス情報(世の中の合意形成が得られている情報)」の中に、自社の正確で有益なデータを組み込ませることです。2026年現在、ChatGPTの月間AI検索シェアは約79%に達し、BtoB選定の8割がAI回答内で完結する「ゼロクリック・ファンネル」へと移行しました。本記事では、AIに推奨されるブランドを構築するための技術的・戦略的アプローチを、実装レベルまで網羅的に解説します。
1. AI検索対策(GEO)の定義と2026年の市場背景
GEOとは何か
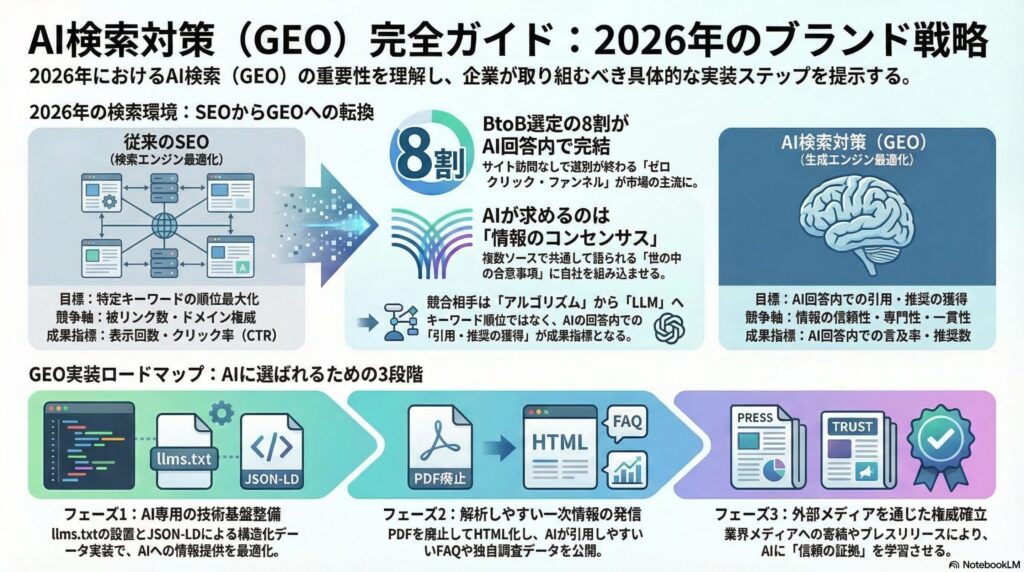
AI検索対策(GEO:Generative Engine Optimization)とは、ChatGPT、Gemini、Claude、Perplexity、Grokといった生成AIによる検索回答において、自社の情報が正確に、かつ優先的に引用されるための最適化施策の総称です。
GEOが既存のSEOと根本的に異なるのは、「競合する相手」が変わった点です。従来のSEOでは、同業他社との被リンク競争やキーワード最適化が主戦場でした。GEOでは、AIモデルの「学習データ」と「RAGによるリアルタイム参照」という2つのレイヤーに対して、自社情報をいかに深く埋め込むかが問われます。AIは単一の「権威ある回答」を生成するため、そこに選ばれなかった企業は事実上、検索上の存在を失います。
従来の検索対策(SEO)との決定的な違い
| 項目 | 従来のSEO | AI検索対策(GEO) |
|---|---|---|
| 対象 | Google・Bingのアルゴリズム | ChatGPT・Gemini・ClaudeなどのLLM |
| 目標 | 特定キーワードでの検索順位最大化 | AIの回答内での引用・推奨の獲得 |
| 競争軸 | 被リンク数・ドメイン権威・KW出現率 | 情報の信頼性・専門性・サイテーション密度 |
| ユーザー行動 | 複数サイトを訪問して比較する | AIがまとめた一つの回答を信頼する |
| 成果指標 | 表示回数・クリック率(CTR) | AI回答内での言及率・推奨ブランド選出数 |
| コンテンツ形式 | テキスト量・KW密度 | 構造化データ・FAQ・一次情報の質 |
| 更新頻度の影響 | クロール頻度に依存 | RAGによるリアルタイム参照で即時反映 |
このテーブルが示すように、GEOはSEOを「置き換える」ものではなく、「上位概念として包含する」施策です。SEOで獲得した被リンクやドメイン権威は、GEOにおける信頼性の証拠として機能します。両者は相互補完の関係にあります。
なぜ2026年に企業にとって重要になったのか
2026年、AI検索は「便利なツール」から「意思決定インフラ」へと変貌しました。この変化を数値で確認します。
普及規模の現実
ChatGPTの月間訪問者数は50億を超えました。GeminiはGoogle Workspaceとの深い統合により、ビジネスパーソンの日常業務ツールとして定着しています。Perplexityは月間検索クエリが前年比4倍以上に拡大し、「事実確認」から「購買前調査」まで用途が広がっています。
ゼロクリック・ファンネルの台頭
BtoB購買調査の場面では、担当者がAIに「このカテゴリのおすすめツールは」と質問した時点で、候補リストが事実上確定します。名前が挙がらなかった企業は比較検討にすら入れません。これを「ゼロクリック・ファンネル」と呼びます。ユーザーが企業のWebサイトを訪問することなく、AIの回答だけで初期選別が完了するプロセスです。
コンセンサス情報の寡占
LLMは、Web上の膨大な情報から「世の中の共通認識」を抽出します。複数の独立した情報源で一貫して言及される企業・製品・概念が、AIにとっての「事実」として固定されます。逆に言えば、自社に関する情報がWeb上で薄い・散漫・矛盾しているほど、AIは「推奨に値しない」と判断します。
サイレント失注の深刻化
最も警戒すべきは「自社が知らないうちに失注している」状況です。顧客はAIに質問し、競合他社を選び、問い合わせすら来ない。この「サイレント失注」は従来のアクセス解析では補足できず、GEOへの対応なしには発見も防止もできません。
2. 【技術深掘り】AIが情報を生成する仕組みと引用ロジック
AI検索対策を実践するには、AIがどうやってWebから情報を参照しているかを技術的に理解する必要があります。現在の主流アーキテクチャはRAG(Retrieval-Augmented Generation:検索拡張生成)です。
RAGの3ステップと自社への影響
ステップ1:検索(Retrieval)
ユーザーが質問すると、AIはまず信頼できるWebサイト(インデックス)から最新情報をリアルタイムで検索します。この「信頼できるWebサイト」に自社ドメインが含まれているかどうかが、第一の関門です。技術的には、AIクローラー(GPTBot、Google-Extended等)がクロールを許可されたページのみが参照候補となります。
ステップ2:拡張(Augmentation)
検索した複数ソースの中から、質問に関連する部分をベクトル検索で抽出します。ここで重要なのは「意味的類似性」です。単純なキーワードマッチではなく、質問の意図と文書の意味的な近さによって選別されます。このため、同義語や関連概念をカバーする多様な表現でコンテンツを記述することが効果的です。
ステップ3:生成(Generation)
抽出したデータに基づき、LLMが自然な文章で回答を作成します。ここで「引用」が発生します。複数のソースで同じ事実が記述されているほど、その情報は回答に採用されやすくなります。
アテンション・メカニズムと信頼スコア
AIはアテンション・メカニズムにより、文脈の中でどの情報を優先するかを重み付けします。信頼スコアを高める要因として実証されているのは以下の通りです。
- ドメイン権威:高品質なバックリンクを保有するドメインからの情報は重み付けが高い
- 一次情報性:独自調査・実験データ・オリジナルの統計は引用率が高い
- 複数ソースの一貫性:複数の独立したドメインで同一の事実が記述されている場合、その情報は「コンセンサス」として固定される
- 更新鮮度:RAGは最新情報を優先するため、定期更新されたページは有利
- 構造の明確さ:セマンティックHTML・JSON-LDで構造化されたコンテンツはパース精度が高い
RAGフレンドリーなHTML構造の具体的実装
AIクローラーは、人間以上に「構造」を読み取ります。以下の実装差が引用率に直結します。
セマンティックタグの活用<div>だらけのHTMLは、AIにとって意味の解析が困難です。以下のように書き換えます。
<!-- Before(AIが解析しにくい) -->
<div class="content">
<div class="title">GEOとは何か</div>
<div class="text">GEOはGenerative Engine Optimizationの略で...</div>
</div>
<!-- After(AIが直接解析できる) -->
<article>
<h2>GEOとは何か</h2>
<p>GEOはGenerative Engine Optimizationの略で...</p>
</article>FAQスキーマの実装
AIは「質問と回答」の対応関係を直接引用します。<details>タグやFAQスキーマは、AIが回答を生成する際の「テンプレート」として機能します。
<div itemscope itemtype="https://schema.org/FAQPage">
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<h3 itemprop="name">GEO対策に必要な期間はどれくらいですか?</h3>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<p itemprop="text">初期変化は2〜4週間で確認できますが、コンセンサス定着には3〜6ヶ月を要します。</p>
</div>
</div>
</div>リスト形式の優先
AIは箇条書き(<ul>、<li>)を情報の要約として認識しやすく、回答にそのまま引用する確率が高まります。長い説明文よりも、明確な箇条書きのほうが引用採用率が高いというデータが複数の研究で示されています。
3. 【実装ガイド】AIクローラー制御と「llms.txt」の書き方
Web担当者が2026年に真っ先に実装すべきは、AI専用の指示ファイルと、クローラーごとの戦略的制御です。
llms.txtとは何か、なぜ必要か
llms.txt は、AIに対して「このサイトのどの情報を参照し、どの文脈で解釈すべきか」を伝えるプレーンテキストファイルです。Webサイトのルート(https://example.com/llms.txt)に配置します。
人間向けのsitemap.xmlがクローラーに「どのページが存在するか」を伝えるのに対し、llms.txtはAIに「どのページが重要で、どのように解釈すべきか」を伝える点が本質的に異なります。2025年後半から主要AIプロバイダーが参照を開始し、2026年現在では実装の有無が引用率に有意差を生むことが確認されています。
llms.txtの完全な書き方
# [会社名]の公式情報ガイド
## Summary
LIFRELLは、BtoBマーケティングとAI活用支援を専門とする日本のデジタルマーケティング企業です。
SEO・コンテンツ戦略・GEO対策の領域で100社以上の支援実績を持ちます。
## Core Services
- [サービス比較表](/services/comparison): 各プランのスペックと最新価格。毎月更新。
- [導入事例](/case-study): 業種別の成功実績と定量的な成果データ(ROI・CVR改善数値含む)。
- [著者・監修者プロフィール](/experts): 業界15年以上の専門家による監修体制の詳細。
- [GEO用語集](/glossary): RAG・LLM・ゼロクリック等の専門用語の正確な定義。
## Data & Research
- [2026年AI検索動向レポート](/research/ai-search-2026): 独自調査に基づく統計データ。
- [業種別GEO成功事例](/research/case-by-industry): 製造業・SaaS・医療等の実装比較。
## What This Site Is NOT About
- 個人向けSNS運用、フォロワー獲得施策
- 暗号資産・投資商品の推奨
## Contact & Verification
公式情報の確認:press@lifrell.co.jp
最終更新:2026年3月クローラーの個別制御:robots.txtの戦略的設計
robots.txt を使い、AIボットごとに異なるアクセス許可を設定します。すべてのボットに同じ設定を適用するのは機会損失です。
# Google検索・Gemini連携(最優先)
User-agent: Google-Extended
Allow: /
Disallow: /internal/
Disallow: /draft/
# OpenAI ChatGPT(汎用回答・最大シェア)
User-agent: GPTBot
Allow: /
Disallow: /internal/
# Anthropic Claude(高度な論理・技術回答向け)
User-agent: ClaudeBot
Allow: /
Allow: /tech/
Allow: /whitepaper/
# Perplexity(リアルタイム検索・ニュース重視)
User-agent: PerplexityBot
Allow: /news/
Allow: /press/
Allow: /research/
Disallow: /archive/
# Meta AI(将来対応)
User-agent: FacebookBot
Allow: /
# 学習データへの利用を拒否したいボット
User-agent: CCBot
Disallow: /各ボットの戦略的位置づけ
- Google-Extended:Google検索結果とGeminiの両方に影響するため、最優先で全ページを開放します。拒否した場合、GoogleのAI Overview(旧SGE)から除外されるリスクがあります。
- GPTBot:ChatGPTの汎用回答に使われます。シェア79%という現実から、基本的には全許可が推奨です。ただし競合他社への流用が懸念される機密資料は除外します。
- ClaudeBot:Claudeは技術文書・論文・ホワイトペーパーを高く評価します。技術的な専門ページを重点的に許可し、引用文献としての地位を確立します。
- PerplexityBot:リアルタイム性を重視するため、プレスリリース・最新調査データのページを優先開放します。
4. 業種別・GEO成功シナリオ:AIに引用されるキラーコンテンツ
製造業(BtoB)
製造業でGEOが最も効果を発揮するのは「スペック検索」です。エンジニアがAIに「引張強度500MPa以上で軽量な金属部品を扱うサプライヤーは」と質問するケースが増えています。
優先実装
技術スペックの比較表をPDFからHTMLテーブルへ移行します。AIはPDFの解析よりもHTMLの数値データを優先的に参照します。非公開になりがちな図面データも、主要な寸法・材質・耐久性をテキストで「言語化」することで、AIのスペック検索にヒットさせられます。
<!-- 製造業向けGEOコンテンツ例 -->
<table>
<caption>アルミ合金A6061-T6の主要スペック</caption>
<tr><th>特性</th><th>数値</th><th>単位</th></tr>
<tr><td>引張強度</td><td>310</td><td>MPa</td></tr>
<tr><td>比重</td><td>2.70</td><td>g/cm³</td></tr>
<tr><td>熱処理</td><td>T6焼入れ</td><td>—</td></tr>
</table>一次情報戦略:自社工場での実測データ・品質試験結果・第三者機関認証情報を公開します。AIは「独自データ」を高く評価し、業界平均値の引用ではなく一次情報として参照します。
SaaS・ITサービス
SaaS領域では「ツール選定クエリ」が最も重要です。「CRMツール 中小企業向け 連携機能豊富」のような複合的なクエリに対して、AIは連携情報の網羅性で回答の根拠を選びます。
APIドキュメントの一般公開
連携可能なツールの一覧と具体的な連携方法を構造化して公開します。AIは「〇〇と連携できるCRMは」という質問に対し、ドキュメント内の連携情報を直接クロールして回答します。ドキュメントをログイン壁の内側に置いている場合、AIは参照できません。
ユーザーレビューの構造化
導入企業の声を schema.org/Review でマークアップします。AIは量的なレビュー数と質的な評価内容の両方を参照するため、実名・実績数値入りのレビューが引用採用率を高めます。
{
"@type": "Review",
"author": {"@type": "Organization", "name": "株式会社〇〇"},
"reviewRating": {"@type": "Rating", "ratingValue": "5"},
"reviewBody": "導入後3ヶ月でリード獲得数が42%増加。MAとの連携もAPIで容易に実装できた。"
}コンサル・専門職
コンサルティング会社・弁護士・税理士・医療機関など、専門性が競争優位の業種では、AIの「E-E-A-T評価」が決定的です。
Web白書への移行
PDFのホワイトペーパーを卒業し、Webページ(HTML)として全文公開する「Web白書」へ移行します。AIが論理構造を直接読み取れるようになることで、Claudeのような高度な推論型AIが「深い考察」の出典として自社を引用するようになります。同じ内容でも、PDF内のテキストよりHTMLで公開されたテキストのほうが引用される確率は有意に高まります。
著者権威の明示schema.org/Person を使い、著者の資格・所属・実績を構造化します。
{
"@type": "Person",
"name": "山田 太郎",
"jobTitle": "シニアマーケティングコンサルタント",
"knowsAbout": ["GEO", "BtoBマーケティング", "AI活用戦略"],
"hasCredential": "Googleアナリティクス認定資格・HubSpotパートナー認定"
}不動産・建設
物件データだけでなく、地域情報(学区、地盤、ハザードマップ)と自社の実績を構造化データ(JSON-LD)で紐付けます。AIは「子育てに最適なエリアの物件は」という文脈の深い検索に対し、信頼できるデータを保有する業者を優先的に紹介します。
地域情報はオープンデータ(国土地理院・各自治体のハザードマップ)を引用・加工して自社コンテンツに組み込みます。一次ソースへの明示的なリンクを含めることで、AIは自社サイトを「信頼できる二次情報源」として位置づけます。
医療・ウェルネス
医療領域はAIが最も慎重に情報源を選別するカテゴリです。Googleの「YMYL(Your Money or Your Life)」の概念がAIにも適用されており、根拠が不明確な情報は参照されません。
エビデンスリンクの徹底
各主張に対して、PubMed・厚生労働省・学会ガイドラインへのリンクを付けます。AIは情報の「裏付け」を確認するため、アウトバウンドリンクの質も参照判断に影響します。
専門家の実名監修
医師・薬剤師・栄養士など国家資格保有者が実名で監修していることを構造化データで明示します。AIは「専門家が確認した情報」を優先的に引用します。
5. AIガバナンスとブランド保護:ハルシネーション対策
AIが自社について不正確な情報を生成した場合(ハルシネーション)、従来のSEOとは異なる対応が必要です。ネガティブな口コミの削除申請のような「防御的対応」ではなく、「正確な情報で上書きする攻勢型」が有効です。
誤情報への技術的アプローチ
AIは「最新かつ構造化されたデータ」を優先します。ハルシネーションを確認したら、以下のステップを踏みます。
Step 1:正式ファクトシートの作成/official-facts/ のようなURLに「[社名]に関する公式情報ファクトシート」を設置します。設立年・従業員数・事業範囲・受賞歴・代表者名等を、JSON-LDで構造化してマークアップします。
Step 2:構造化データによる上書き
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "株式会社LIFRELL",
"foundingDate": "2019",
"numberOfEmployees": {"@type": "QuantitativeValue", "value": 45},
"areaServed": "JP",
"description": "BtoBマーケティングとAI活用支援を専門とする日本の企業。GEO・SEO・コンテンツ戦略の領域で100社以上の実績。",
"sameAs": [
"https://www.linkedin.com/company/lifrell",
"https://twitter.com/lifrell_official"
]
}Step 3:外部権威ドメインへの露出
AIは古い不正確なブログよりも、大手メディア・業界団体・政府機関の記述を「正」として優先します。プレスリリース配信・メディア取材・業界団体への加盟情報公開を通じて、信頼性の高いドメインから自社の正確な情報が参照される環境を構築します。
ダークGEO対策
競合がAIに対し、自社へのネガティブな評価を学習させようとする行為(フェイクレビューの大量生成・不正確な比較記事の流布等)が2025年以降観測されています。
これを防ぐ最も有効な手段は「信頼の先積み」です。権威あるドメインからの言及を継続的に積み上げることで、後から流入する不正確な情報の影響を稀釈できます。具体的には、大手業界メディアへの寄稿・学会・行政との連携実績の公開・外部格付け機関への登録が有効です。
6. 2026年のAI検索予測:マルチモーダルとエージェント
マルチモーダルGEOの到来
現在のAI検索はテキストが主軸ですが、2026年後半から2027年にかけて、画像・音声・動画を直接ソースとする「マルチモーダルRAG」が主流になると予測されています。
画像の最適化
すべての画像に詳細なAltテキストを設定します。AIは画像内の文字(OCR)や画像の意味(Vision AI)を読み取り、テキストコンテンツと同等に検索ソースとして扱います。
動画コンテンツの構造化
YouTube動画の字幕(トランスクリプト)を完全に最適化します。AIはYouTubeのトランスクリプトをリアルタイムに参照する仕組みを持ち始めています。商品説明・専門家解説・事例紹介動画のトランスクリプトは、テキストコンテンツと同様にGEO施策の対象です。
インフォグラフィックのテキスト化
グラフや図表の内容を、同一ページ内にテキストでも記述します。AIはPNG内の数値を読み取れない場合があるため、表形式のテキストデータを必ず併記します。
AIエージェントによる自動購買
2027年以降、BtoBの初期選定プロセスが人間ではなくAIエージェントによって実行される事例が増加する見通しです。企業の調達担当が「予算200万円以内で、Salesforceと連携でき、日本語サポートがある MAツールを選定して契約直前まで進めて」とAIに指示する世界が近づいています。
この時、AIエージェントが判断基準にするのは、人間向けの感情的なコピーではなく「仕様・価格・利用規約・APIの柔軟性・SLA・セキュリティ認証」という純粋なデータです。
AIエージェント対応チェックリスト
- 価格表はHTMLテーブルで公開し、機械が読み取れる形式にする
- APIドキュメントに連携先ツール一覧を明示する
- セキュリティ認証(ISO27001・SOC2等)の取得状況を構造化データで表現する
- 利用規約・プライバシーポリシーのURLを
llms.txtに明記する - 契約・見積もりフローをテキストで説明したページを設ける
7. GEO施策の優先順位と実装ロードマップ
フェーズ1(0〜1ヶ月):基盤整備
まず「AIに読み取られない状態」を解消します。
llms.txtの作成・設置robots.txtのAIボット別設定- 主要ページへの
schema.orgJSON-LDマークアップ(Organization・FAQPage・Article) - 全画像のAltテキスト設定
- PDFコンテンツのHTML移行(最重要5ページから着手)
フェーズ2(1〜3ヶ月):コンテンツ強化
AIに「引用したくなるコンテンツ」を整備します。
- 業種別・課題別のFAQページ新設
- 独自調査・数値データを含むオリジナルレポートの公開
- 著者権威ページ(専門家プロフィール)の構造化
- 競合比較コンテンツの公開(客観的・一次情報ベース)
- 用語集・定義ページの整備(AIの参照文献化を狙う)
フェーズ3(3〜6ヶ月):権威の外部化
AIが「信頼できる外部ソース」から自社を認識する状態を構築します。
- 業界メディアへの寄稿・インタビュー掲載
- 学会・研究機関との連携実績の公開
- プレスリリース配信(構造化フォーマットで)
- Wikidata・業界データベースへの登録
- ポッドキャスト・ウェビナーの書き起こしコンテンツ化
効果測定の方法
GEOの効果は従来のアクセス解析では可視化できません。以下の独自計測を実施します。
- AI言及率モニタリング:週次でChatGPT・Gemini・Perplexityに自社カテゴリのクエリを入力し、自社が言及されるか・どのような文脈で言及されるかを記録します
- 引用ソース確認:Perplexityは参照元URLを表示するため、自社ドメインが引用されているかを確認できます
- コンバージョン経路の変化:「AIで見て問い合わせた」というユーザーの増加を、流入経路調査やフォームの「知ったきっかけ」設問で把握します
まとめ:AI検索対策は「デジタル上の信頼資産」の構築だ
AI検索対策(GEO)は、短期的なテクニックの集合ではありません。Web上に「信頼できる事実」を積み上げ、AIという究極の情報キュレーターを通過させる中長期の資産形成プロセスです。
技術的実装(llms.txt・構造化データ・クローラー制御)は「入口を開ける」作業です。それだけでは不十分で、AIが「引用したい」と判断するコンテンツの質と、「信頼できる」と判断するための外部権威の積み上げが不可欠です。
2026年、AIに選ばれる企業になることは、デジタル競争における「生存権」の確保です。競合他社が対応を後回しにしている今が、コンセンサス情報を先占できる最後の機会かもしれません。
FAQ
Q1. AI検索対策に必要な予算はどのくらいですか?
フェーズ1の基盤整備(llms.txt・robots.txt・JSON-LD)は、既存の開発リソースで対応可能な場合がほとんどです。コンテンツ強化フェーズ以降は、月30〜100万円規模の投資が効果を加速させます。外部メディア露出やPR施策を組み合わせる場合はさらに予算が必要です。Q2. 効果が出るまでの期間はどれくらいですか?
llms.txtやクローラー設定の変更は、AIのクロール周期(通常2〜4週間)で反映が始まります。コンテンツの引用率向上には3〜4ヶ月、「コンセンサス情報」としての定着には6ヶ月以上を要する場合があります。Q3. SEOとGEO、どちらを優先すべきですか?
両立が必須です。SEOで獲得したドメイン権威・被リンクはGEOでも信頼性の根拠として機能します。SEOを犠牲にしてGEOに専念することは、土台を壊して建物を建てるのと同じです。既存のSEO施策をGEOフレンドリーに「アップグレード」するアプローチが最も効率的です。Q4. 中小企業でもGEO対策は有効ですか?
むしろ有効です。AIはドメインの規模よりも「情報の専門性と信頼性」を評価します。特定のニッチ領域で圧倒的に詳細な情報を持つ中小企業が、大手を差し置いてAI回答に採用されるケースが多く確認されています。Q5. ハルシネーション(誤情報生成)が起きた場合、どう対応すればよいですか?
まず自社の正確な情報を構造化データ(JSON-LD)でFactSheetページに整備します。次に、大手メディアや業界団体への掲載を通じて「正しい情報」を外部権威ドメインから発信します。AIは新しく権威ある情報で古い誤情報を上書きします。AIプロバイダーへの直接報告窓口(OpenAI・Googleは対応フォームあり)も活用します。
LIF Tech編集部
グローバルマーケティングとAI活用を専門とする編集チーム。欧州・アジアのカンファレンスや現地取材を通じて、日本のマーケター・経営者に向けた実務的な情報を発信しています。
